Extract value from your data without fear
Leverage your sensitive data assets in a safe and protected manner that complies with data privacy regulations.


How Privly works
Anonymize big datasets within minutes.
Privly’s core anonymization capabilities

Auto-Discover
Organizations can choose to either mask or redact personal identifiable information.
Masking replaces data profiles with inauthentic information that follows the same structure. On the other hand, redaction blocks the selected data profiles.

Poly-Anonymization™
When each piece of information (name, address, mobile number, etc.) is masked or redacted, Privly swaps it with a Poly-Anonymous Identifier (Poly-ID).
Each Poly-ID is unique, inconsistent, unpredictable, has multiple potential values and is not hashed.

Data matching
Because every anonymized datapoint has a Poly-ID, Privly users can combine multiple datasets in a way that matches records at the individual level without revealing personal identifiable information.
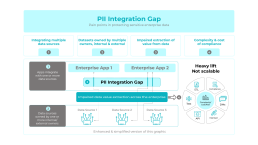
PII Integration Gap
Pain points in protecting sensitive enterprise data
Integrating multiple data sources
Impaired extraction of value from data
Datasets owned by multiple owners, internal & external
Complexity & cost of compliance
Setting up Privly is easy

Using Privly doesn’t entail any coding. It also won’t require you to retrofit your enterprise systems.

Setting up and operating the service doesn’t affect other enterprise systems.

Privly connects with any database. It also doesn’t require any database expertise.

The solution is delivered to your enterprise systems through a Docker Container.

All data processing through Privly occurs inside of your enterprise firewall.

When anonymizing personal data, Privly doesn’t expose or rewrite the original data in your databases.

Privly connects with any database from numerous data sources, internal or external to your business.

Users can easily configure rules of anonymization, automation, storage, data matching, and other tools.
Privly protects your data through our proprietary
Sundering technology
Sundering prevents our clients’ data from being read at rest but allows Privly to search and join data values without having to decrypt entire database tables. It offers all the advantages of encryption without its limitations.
Our patent-pending Sundering technology parses datasets into components, and then obfuscates these elements so they cannot be recombined without the presence of unique, multi-part Sunder Keys.
Upon the creation of a Privly account, the service provides the account holder with their half of a Sunder Key, a value our solution never stores. This half of the Sunder Key is only provided to us upon a web service call from the client’s account, which combines it with our half of the Sunder Key. This triggers the work and anonymization process within Privly.
The service never stores both halves of a key, making the data secure at rest. This means that
